The Berkeley Function-Calling Leaderboard
Function-calling (aka tool-use) is essential to enable LLMs to run internet searches, write and execute code, generate images, use a calculator, … whenever that makes sense to solve the current task. The Berkeley Function-Calling Leaderboard gives a good overview of which LLMs perform best on function-calling benchmarks.
Here is what the leaderboard looks like currently:
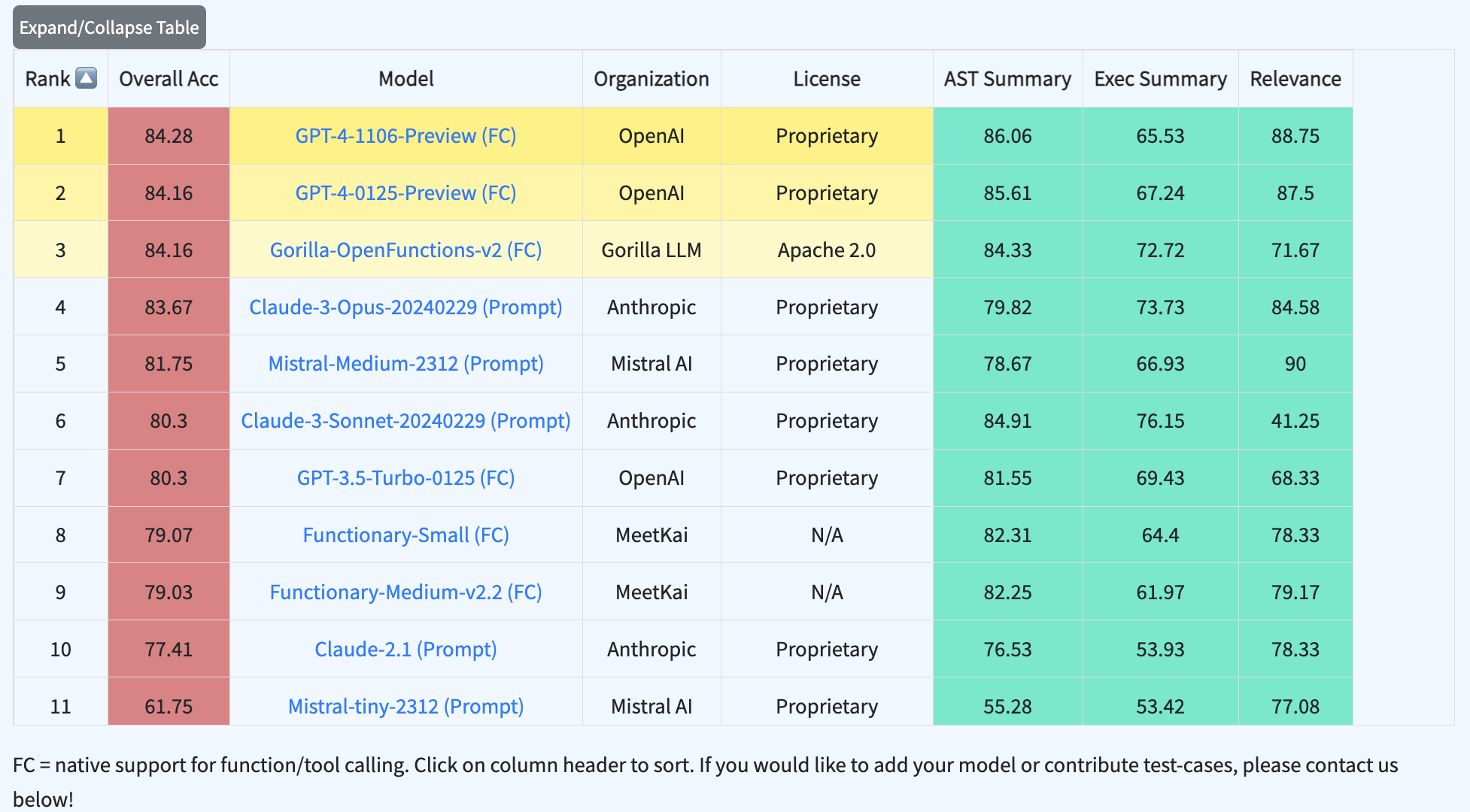
Noteworthy
A few things stand out to me:
an open source model, Gorilla OpenFunctions v2, that is Apache 2.0 licensed, code included and comes with an open dataset performs on par with GPT-4.
we are still quite far away from “solving” function-calling, especially when subsequent or parallel calls are needed. If an individual function call succeeds with 90% chance, the chance of getting say five function calls right in a row is 0.9^5 ~ 60%, assuming independence. This explains the scores in this range for the more complex tasks on the leaderboard and also hints that “solving” these multi-step tasks (e.g., getting to ~95%+ success rates) will require a lot more work.
the blog post announcing the Function-Calling Leaderboard has an interesting section on common mistakes made by LLMs. Reading this, I wonder a) if a simple chain-of-thought prompting would help fix/some most of these, and b) how good the best-performing LLMs actually are at picking from a host of functions. Point b) is quite a severe limitation in my experience and warrants a bit of extra work to remedy, e.g., an embedding-based ranking of the function based on their description before letting the LLM choose from the top-K functions.






