Experimenting with ML-powered search in Amazon Kendra
Amazon Kendra is a managed search service offered by AWS. Using machine learning/natural language processing, Kendra is able to “understand” both search queries and the documents searched to answer questions directly or to perform a keyword-based search.
Kendra is fully-managed by AWS which means that, as a developer, I do not need to worry about managing infrastructure, as, for example, required by open source alternatives like Jina for neural search or Haystack for Question-Answering.
In this short post, I want to give Kendra a spin and search a small dataset of podcast episode show notes and episode transcripts. Note that Kendra is really meant to power search in larger enterprises, reflected in its pricing model. But there is a 30-day free trial allowing developers to explore the tool and see what it is capable of. This is what I am doing in this post.
Data
I downloaded the show notes and transcripts for 20 episodes of Python-focused podcasts (Talk Python to Me and PythonBytes) and stored them as flat text files in an S3 bucket.
Deployment
CloudFormation templates deploying Kendra, setting up an S3 bucket as a Kendra data source and defining the necessary AWS roles are available on GitHub.
Results
Using Kendra’s default search interface, I tested both question- and keyword-based searches:
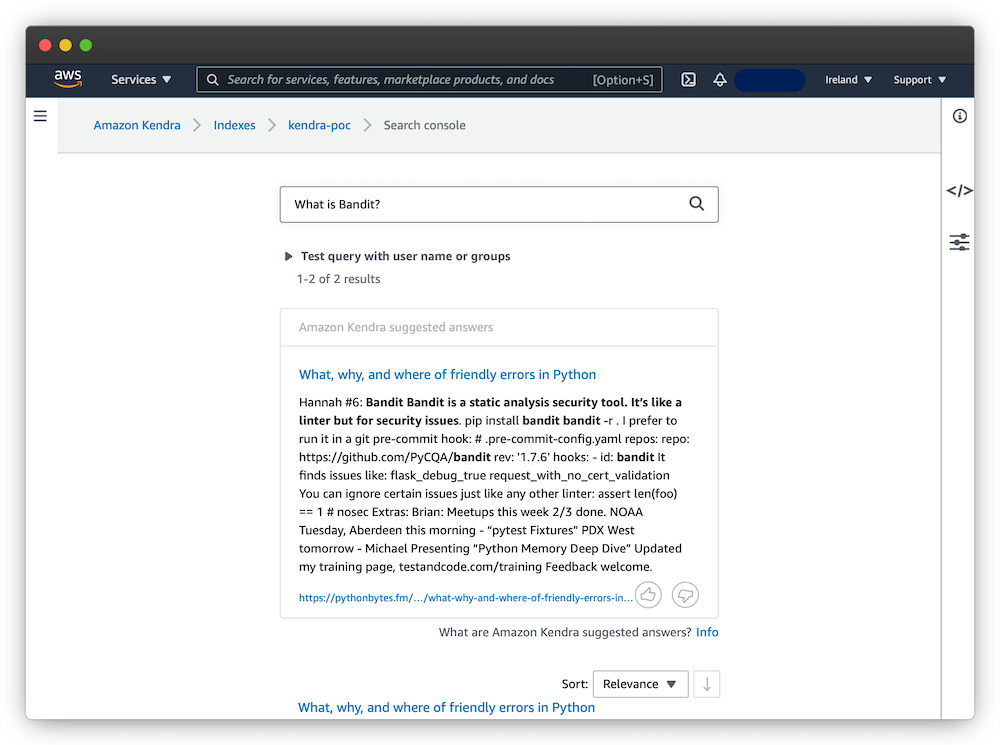
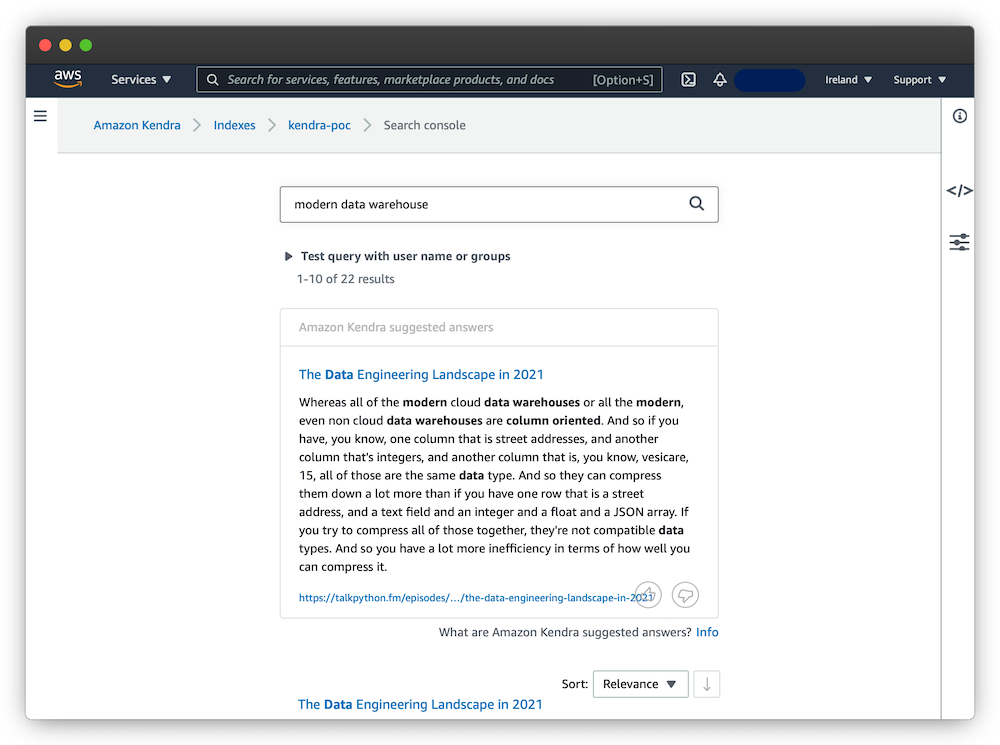
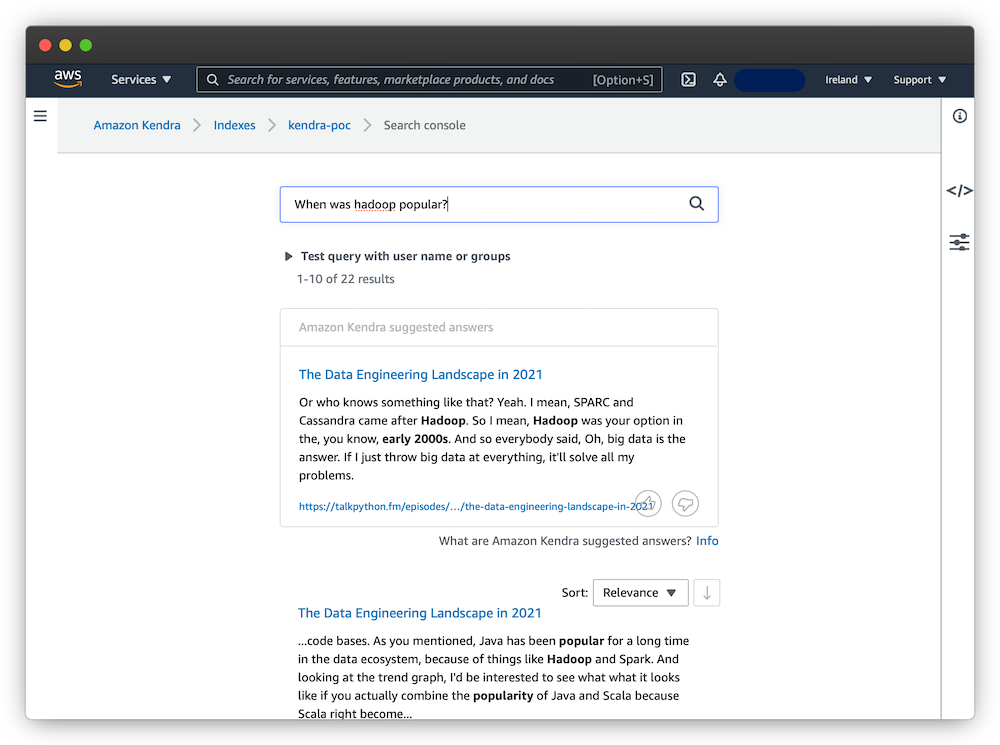
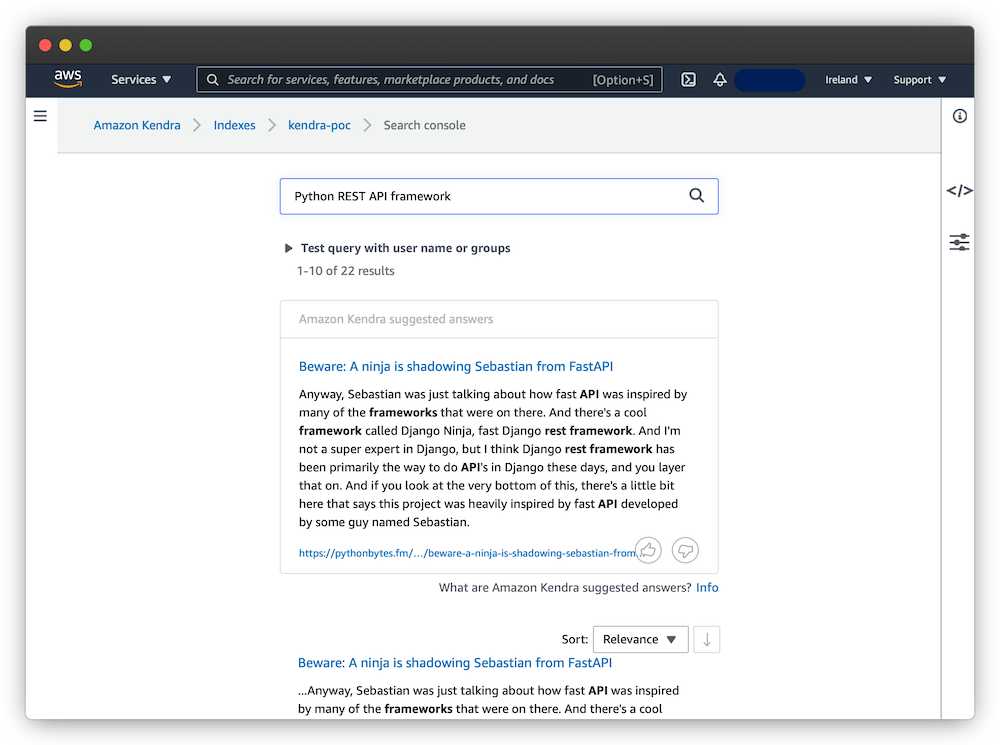
Overall, the results look useful and Kendra is able to surface relevant information. A logical next step would be to use this demo to show it to potential users/stakeholders, together define a search scope of interest and implement a larger proof-of-concept.
Conclusion
Here is what I think about Amazon Kendra based on this small trial:
- as a managed service, Kendra is able to deliver meaningful search results quickly - this is ideal to build a rapid prorotype
- loading data from S3 is easy and plenty of other connectors are available to make documents searchable
- supports file formats such as flat files, PDFs, Word documents or PowerPoint presentations
- adding metadata and API access allow customization via faceted search, access restrictions for specific user/groups etc.
- expensive for small user groups with few queries - Kendra is clearly made to serve larger enterprises






