Recommending scientific articles interactively
TL;DR
There are too many interesting research papers to read. This article describes an approach to recommend papers using user feedback and pretrained paper embeddings. Check the live app here or see the source code on GitHub.
The app in action looks like this (no sound, just a video) - read on if you want to know how it works:
Why?
There are simply too many interesting research papers out there to read and more are getting published every day. Even sort of keeping up with the literature by skimming titles and abstracts of relevant work on PubMed, arXiv, bioRxiv, medRxiv, and so on is close to impossible. To find interesting papers, I mostly rely on recommendations from citations in articles I read, friends, colleagues, or social media, especially Twitter but LinkedIn is sometimes surfacing relevant items, too.
In this project, I wanted to prototype my own, personal research paper recommendation system that is based on my preferences to supplement recommendations I get from others. I wanted to go beyond text-based searches and use semantic vector representations to separate relevant from irrelevant articles. In short, I wanted to be able to self-curate my own literature recommendations to make better-informed decisions regarding the papers I invest time in reading.
This project is inspired by how I think Semantic Scholar’s research feeds work, although I was not able to find a clear explanation of the underlying algorithm. I also wanted to explore extra features in the paper recommendations, for example, showing how my likes and dislikes influence the papers recommended interactively.
Note that this is an early prototype that I am sure will break and that leaves a lot to be done. Nevertheless, I think it is worth sharing in its current state and I would appreciate any feedback below.
How the recommendations work
1. Search for a paper and similar papers
The initial search is based on your favorite paper’s DOI and searches using the Semantic Scholar API. In addition to the query paper, the search returns similar papers as selected by Semantic Scholar in a table.
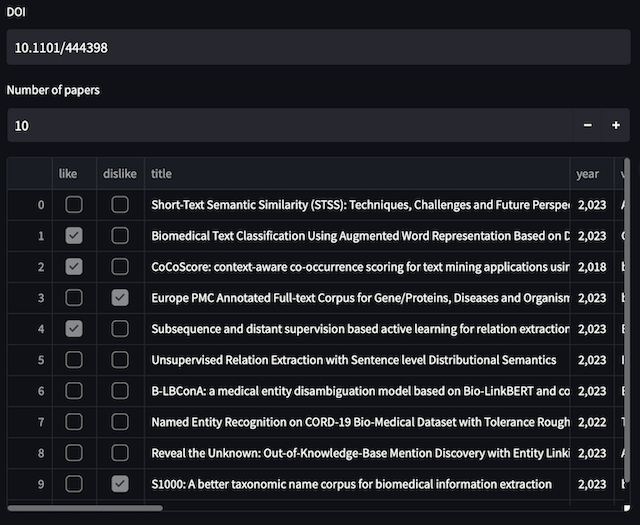
2. Select papers you like and dislike
Select the papers you like and dislike among all papers returned in Step 1 in a simple user interface:
3. Get and explore recommendations based on the papers you liked and disliked
First, search for a follow-up research topic of interest and ask for 5 paper recommendations:
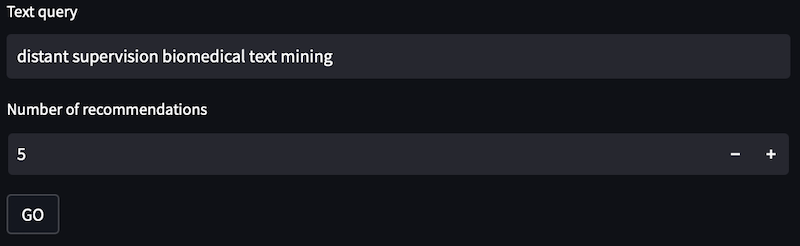
This will look for papers matching the new search and that are similar to papers liked previously and *dis*similar to papers disliked. Afterward, the user can interactively explore how recommendations, liked, disliked, and your initial favorite paper relate to each other:
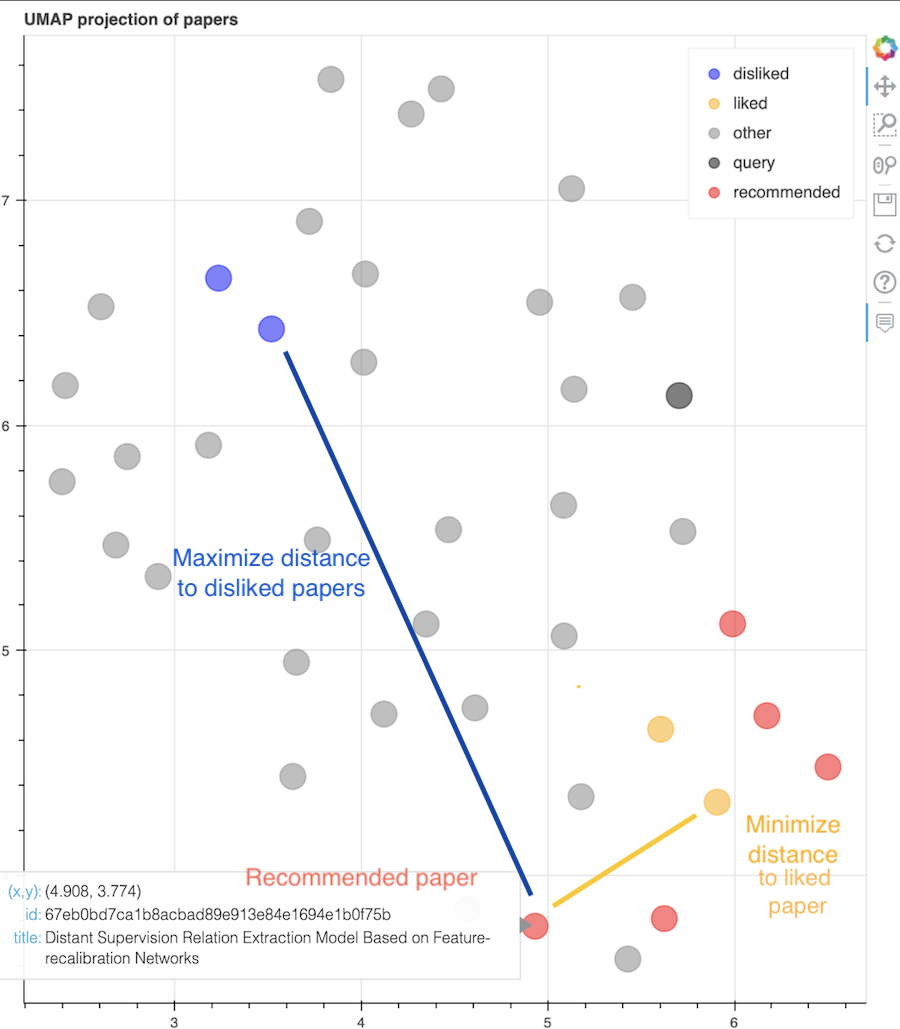
The interactive 2D visualization of the papers is created using bokeh after UMAP projection.
4. Repeat until satisfied with the recommendations or come back another time
Go to Step 1 or 2.
The math behind finding recommendations based on liked and disliked papers
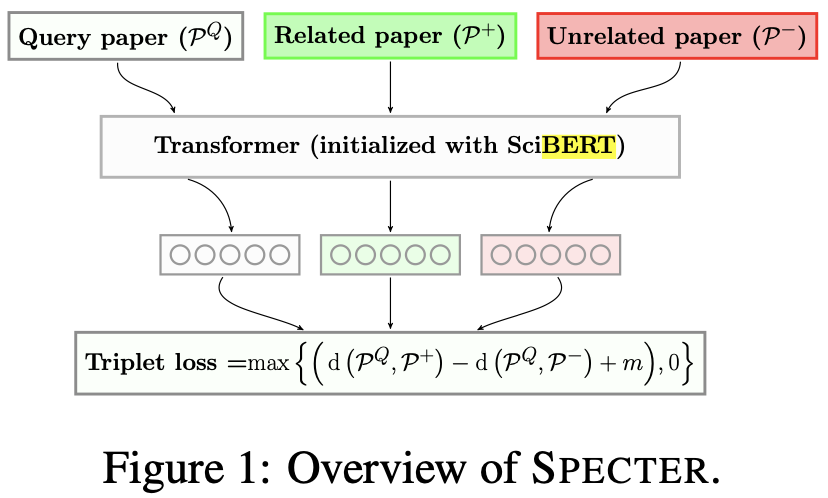
For each candidate recommendation paper, I calculate the cosine distance (1 - cosine similarity) between the candidate paper’s embedding and the embeddings of the liked and disliked papers. I am using SPECTER document-level embeddings here that, in short, are based on SciBERT-document embeddings but further incorporate the literature citation graph during training to generate similar embeddings for papers citing each other using a triplet loss. See the illustration here from the SPECTER paper:
I then sort papers in increasing order by score $\mathcal{S}$ (loosely inspired by triplet loss): $\mathcal{S}(x, L, D)$ = $\text{min}_{l \in L}$ $d(x, l)$ - $\text{min}_{d \in D}$ $d(x, d)$
where $x$ is the query paper, $L$ the set of liked papers, $D$ the set of disliked papers, $d$ is the cosine distance between two embeddings. I.e. we look for papers that are similar to the liked papers but dissimilar to the disliked papers. The paper with the lowest $\mathcal{S}$ gets recommended first. This is a simple heuristic that I am sure could be improved but it seems to work reasonably well for now.
Availability
The app is available here and written using Streamlit.
It is hosted for free on Streamlit Cloud which comes with certain resource limitations.
Please be patient if the app should break but please let me know when it does, e.g., by leaving a comment below.
The app’s source code is available on GitHub with CI/CD setup, i.e., whenever I
push to the main branch, the app is automatically redeployed.
Next steps
There are many improvements to be explored ranging from switching to SPECTER 2 embeddings to adding a chat-like interface to interact with the surfaced papers’ contents or testing better recommendation ranking heuristics.
From a backend perspective, I would love to add user authentication, multiple feeds per user, and a proper backend database to store recommendations across sessions. But this certainly goes beyond this early prototype for now.






