Labeling data in Amazon SageMaker Ground Truth
Acquiring and cleaning data, including reliable labels for supervised learning, determines the fate of every data science project and usually takes up about 80 percent of project time. For an NLP project I am working on (more on that in a later post), I have been looking for a simple tool to label named entities in text. After comparing a few alternatives out there, I decided to use Amazon SageMaker Ground Truth.
The premade named entity recognition (NER) template available in Ground Truth fit my use case and besides specifying input and output data, I only had to set up which NER labels I wanted to use.
I then converted my input data to a simple JSON Lines-formatted manifest file which I uploaded to S3. The file looks like this:
{"source": "First piece of text to label."}
{"source": "Second piece of text to label."}
...
{"source": "Nth piece of text to label."}
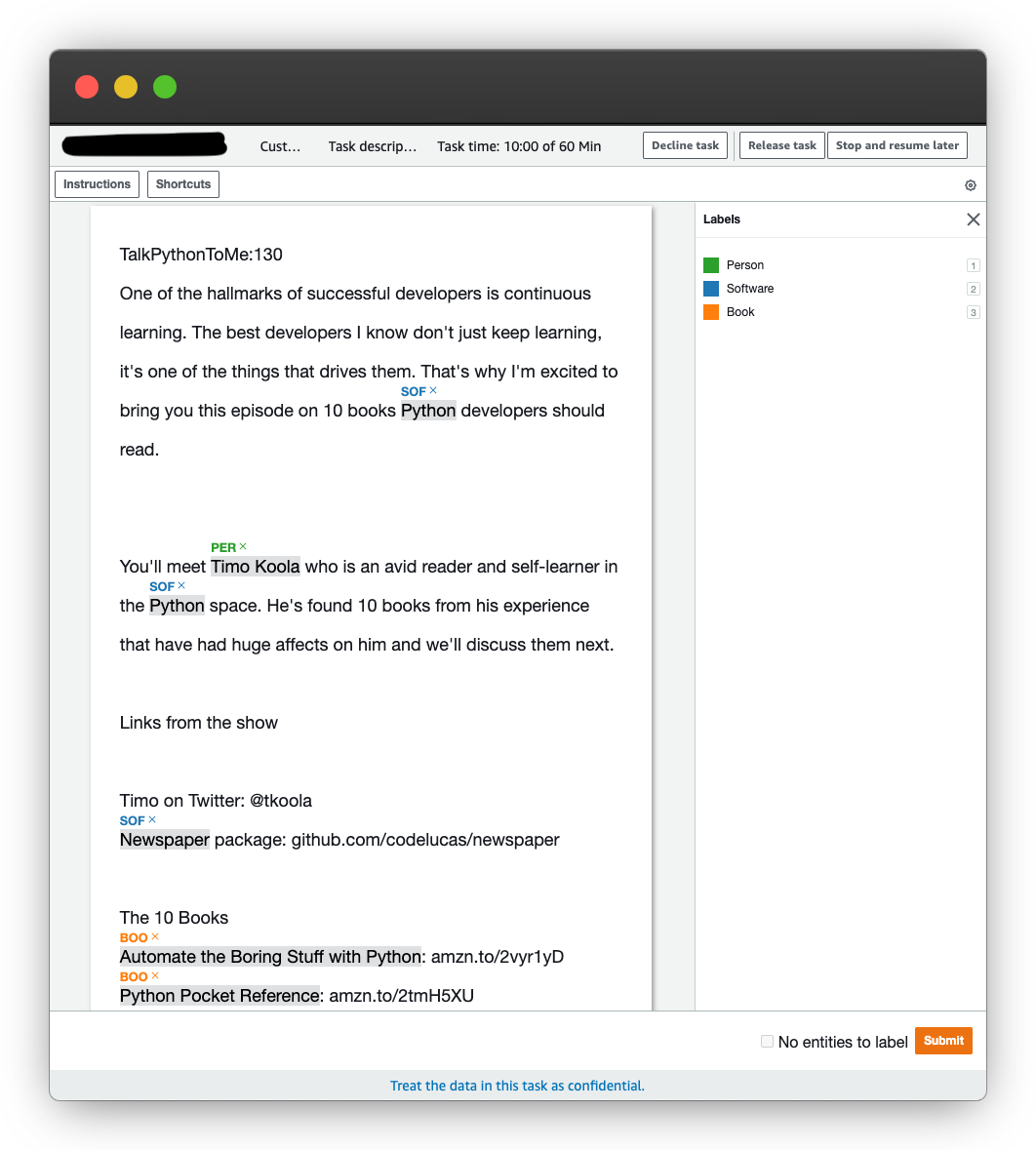
The labeling interface is easy to use and, for example, supports hotkeys for faster labeling of the three label classes I defined as part of my task (Book, Person, Software). Here is a screenshot of the labeling interface:
Output data is also stored in S3 in JSON Lines format.
Besides NER, SageMaker Ground Truth supports text classification and other kinds of text, image and video labeling tasks. The possibility to scale out labeling tasks to teams or crowdsourcing via Amazon Mechanical Turk is also a great option to have. Finally, Ground Truth supports active learning which I am eager to try out once NER tasks are supported.






